As a small side experiment of my PhD thesis, I investigated latencies of ROS message transfers.
I know that I have not been the first person to investigate this and that there are also frameworks for running tests now. I will list here some links if you are interested in what others have already investigated.
Exploring the performance of ROS2
Latency Analysis of ROS2 Multi-Node Systems
Nevertheless, I performed my own experiments because of two reasons. First, I wanted to test it on our specific hardware (the humanoid robot Wolfgang-OP). Second, the previous works did not use the EventExecutor and message frequencies. For reasons on why we need to use the EventExecutor, see our previous post here.
Experimental Setup and Influence of the Idle Function
If you want more details on the robot that I used, you can find it here.
In these experiments, the main computer of the robot was already upgraded to an ASUS PN51-E1 with Ubuntu 22.04. The latencies were just measured for a single transfer between a sender and a receiver (no ping-pong or multi node setups). We each recorded messages for 100s after discarding
the first 100 messages, which often had high outliers as nodes were still starting. We were interested in the latencies for messages that control the robot’s joints (since quick reactions to disturbances are crucial in a bipedal robot), and therefore, we used a small joint command message for our tests. Please keep in mind that our results might not apply for larger messages like images or pointclouds.
Naturally, it is important how the nodes of the sender and the receiver node are executed. ROS 2 allows to run them in two separate processes or in a single process (which we tested both). It is also important how this process(es) are then executed by the operating system. We forced Ubuntu to run these on isolated cores by using “taskset” and “isolcpus” (see our previous post for more infos about this). Additionally, we realized that it is important to deactivate the idle function of the CPU as it has a high influence on the latency (see image below). You can deactivate it in Ubuntu with the following command:
echo 1 | sudo tee /sys/devices/system/cpu/cpu∗/cpuidle/state∗/disable > /dev/null

Executor
As stated above, we need to use the EventExecutor for performance reasons in our system. Still, I was interested how it performs in relation to the other standard executors. For this small sender-receiver setup, the CPU usage of the executor is not important. Therefore, we could test all of them without further issues. We used a frequency of 1000Hz in this experiment. The difference between the executors is small. All of them profit from running the nodes in the same process.
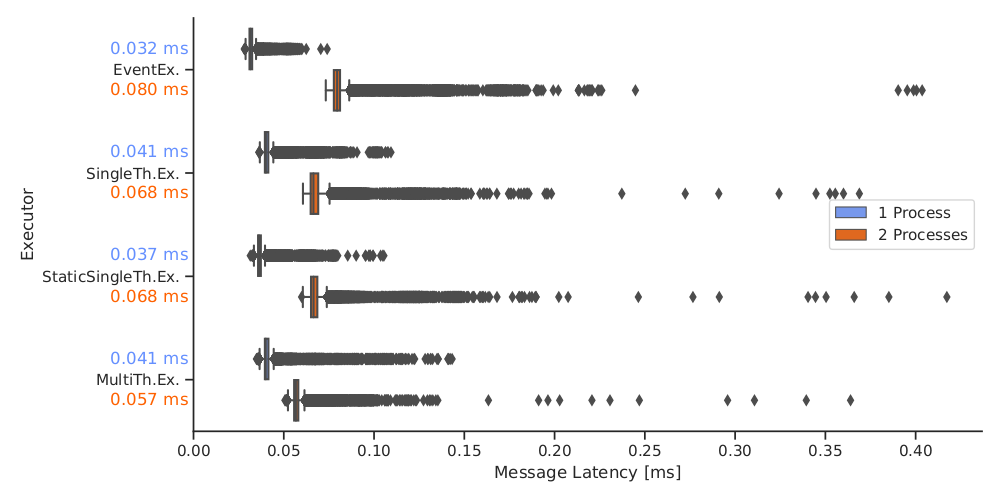
Comparison to ROS 1
While migrating to ROS 2, our team had the impression that there is a large difference between using nodes in Python and using nodes in C++, which was not so large in ROS 1. Therefore, I also compared the performance of the ROS 2 C++ EventExecutor to the ROS 2 Python Executor (no event based implementation exists at the moment for Python), as well as to their counterparts in ROS 1. Naturally, the ROS 1 nodes can not be executed in the same process, therefore, this test case was omitted. The QoS settings for ROS 2 were set to default, as these mimic the ROS 1 behavior best.
The results (see image below) show that the performance of ROS 2 Python nodes is indeed very bad. Using C++, ROS 2 can be faster than ROS 1 but only if the nodes are executed in the same process.
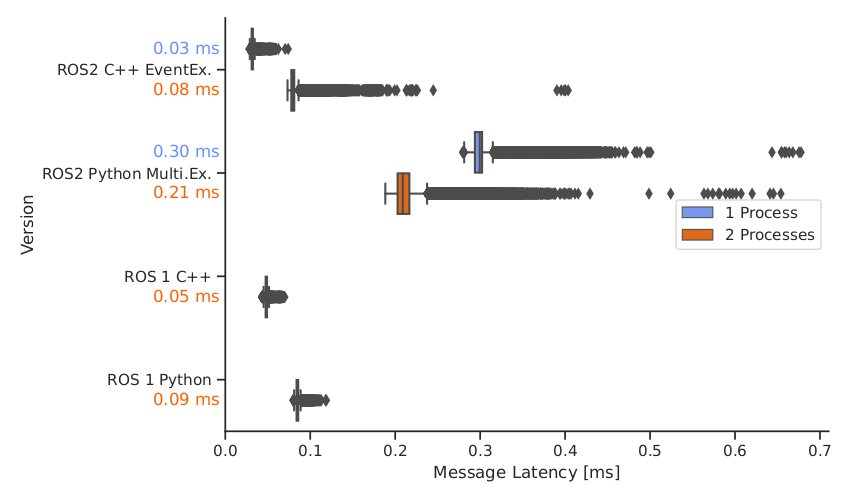
DDS
ROS 2 also allows the usage of different DDS implementations. Naturally, I also tested if this choice might influence the latency. I only tested FastDDS and CyclonDDS, since these are open source.
In our testcase, Cyclone DDS performed better than FastDDS (although the impact of this choice is smaller than, e.g., using the idle function). Previous work (https://ieeexplore.ieee.org/abstract/document/9591166/) indicated that FastDDS has a lower latency. But they only tested frequencies up to 100 Hz.

Integrated Test and Scheduling
After performing these simple sender-receiver experiments, I tested the latencies between two nodes of our motion software stack that were running at 500Hz while the robot was actively walking (and therefore many other nodes were running). Interestingly, the latencies were much higher than in the toy example. After some investigation, it turned out that the Linux scheduler was the problem. In the experiment before, we only had two threads which each had their own core, so there weren’t any issues. Now, in the integrated case, we have many threads running simultaneously. Unfortunately, the used “taskset” command leads to the scheduler to only execute one thread at a time. I solved this issue by setting the Linux scheduler behavior to the round-robin mode.
Interestingly, deactivating the idle function of the CPU still resulted in improved latencies, although the CPU was under high load.
I hope that these insights might help others in reducing the latency of ROS 2 message transfers for high frequency topics.
Did you use the tcp no delay option in the ROS1 implementaton?
Aren t ros1 nodelet under the same node manager running in the same process?
Thanks for the benchmark! Just to not, ROS1 allows running two nodes in the same process – this is called nodelets (C++ only). It would be very interesting to add them to the comparison. I bet they’d win.
Marc knows about them, but sadly did not include nodelets for ROS one as the Bit-Bots migrated to ROS2.
That being said, nodelets are also a mess in my experience and at least in research contexts (without final product deployment) I would always prefer standalone nodes.
I’m sure he used tcp no delay in ROS one.